私たちは統計学の一環として、データ分析を行う際に「標準偏差 いくつ」という疑問を抱くことがよくあります。標準偏差はデータのばらつきを示す重要な指標であり、この数値を正しく理解することが求められます。本記事では、標準偏差の計算方法や実際の例を通じて、どのようにしてこの数値を求めるかについて詳しく解説します。
具体的には、さまざまなケーススタディーや簡単な手順を提示しながら、「標準偏差 いくつ」という問いに対する答えを導き出していきます。私たちと一緒にこのテーマを探究し、自分自身のデータ分析スキルを向上させませんか?あなたもこの知識を身につければ、データから得られる洞察がより深まることでしょう。興味はありませんか?
標準偏差 いくつで計算するかの基本概念
標準偏差は、データのばらつきを示す重要な指標です。私たちが「標準偏差 いくつで計算するか」を考える際には、まずその基本的な概念を理解することが不可欠です。ここでは、標準偏差をどのように算出し、その値が何を意味するのかについて詳しく解説します。
標準偏差とは
標準偏差は、データセット内の各データポイントが平均からどれだけ離れているかを示します。この指標によって、データの分散具合や一貫性を把握することが可能です。一般的に使用される計算方法には以下があります:
- 母集団標準偏差:全てのデータが利用できる場合に用います。
- サンプル標準偏差:全体から一部を抽出して分析するときに適用されます。
計算方法
- データセットの平均(μ)を求めます。
- 各データポイント(x_i)と平均との差(x_i – μ)を計算します。
- この差を二乗し、それらすべての二乗した値の平均(または合計)を求めます。
- 最後に、その平方根を取ります。
このプロセスによって得られる結果こそが、私たちが求める「標準偏差」なのです。
| ステップ | 説明 |
|---|---|
| 1 | 平均との差を求める |
| 2 | それぞれの平均との差の二乗 |
| 3 | 二乗した値の平均または合計 |
| 4 | 平方根を取る |
標準偏差と他との関係
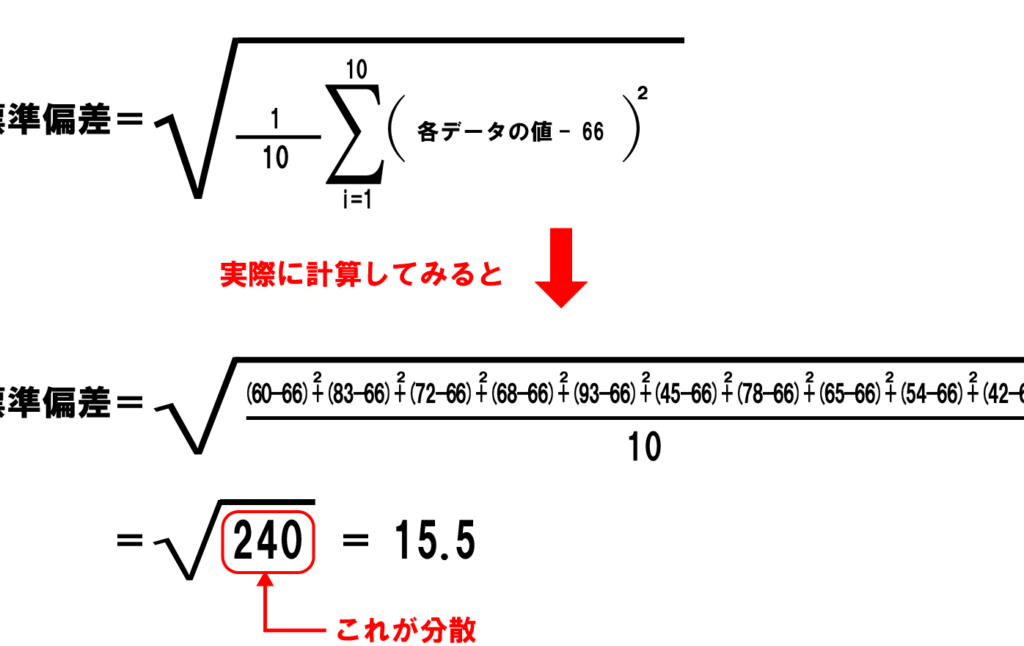
私たちは「標準偏差 いくつ」の具体的な数値だけでなく、その背後にある理論や他の統計指標との関連性も考慮する必要があります。例えば、分散は実質的には標準偏差の二乗であり、この関係性も理解しておくとより深い分析につながります。また、正規分布の場合には、おおよそ68% のデータポイントが平均±1倍の範囲内に収まるため、この特性も知識として活用できます。
標準偏差を求めるための具体的なステップ
私たちが「標準偏差 いくつ」で計算する際には、明確なステップを踏むことが重要です。以下の具体的な手順に従うことで、正確に標準偏差を求めることができます。このプロセスは、データ分析の基礎となり、信頼性の高い結果を得るために不可欠です。
ステップ1: データセットの平均を求める
まず初めに、データセット内のすべての値を足し合わせ、その合計をデータポイントの数で割ります。これによって得られる値が平均(μ)です。この平均は後続の計算において非常に重要な役割を果たします。
ステップ2: 各データポイントとの平均との差を計算する
次に、各データポイント(x_i)から先ほど求めた平均(μ)を引きます。この差は、それぞれのデータポイントがどれだけ平均から離れているかを示しています。
ステップ3: 差の二乗とその合計
上記で求めたそれぞれの差(x_i – μ)について、その二乗((x_i – μ)²)を計算します。そして、このすべての二乗した値を合計します。
ステップ4: 平均または母集団の場合とサンプルの場合で分ける
- 母集団標準偏差:全てのデータが利用できる場合、この合計値をデータポイント数で割ります。
- サンプル標準偏差:一部のみから推測する場合、この合計値を(n – 1)で割ります。ここでnはサンプルサイズです。
その後、この結果に平方根を取ることで最終的な標準偏差が得られます。
| ステップ | 説明 |
|---|---|
| 1 | 全体の平均(μ)の算出 |
| 2 | 各点との平均との差 (x_i – μ) の算出 |
| 3 | (x_i – μ)² を求め、その総和取得 |
| 4 | {母集団またはサンプル} に応じた割り算と平方根取得。 |
このようにして得られる「標準偏差」は、多様なデータセット間でも適用可能な普遍的な指標となります。また、「標準偏差 いくつ」がどれほど意味ある数字かも理解しやすくなるでしょう。
データセットにおける標準偏差の重要性
データセットにおける標準偏差は、私たちが「標準偏差 いくつ」で計算するかを理解する上で非常に重要な指標です。これは、データの変動や散らばり方を示すものであり、特定の値が平均からどれだけ離れているかを把握するための手助けとなります。この情報は、データ分析や意思決定において不可欠であり、信頼性のある結果を導き出す基盤となります。
標準偏差が低い場合、そのデータセット内の値は互いに近いことを意味し、高い場合は逆に値が広範囲に分布していることを示します。このような特性は、以下の理由から特に重要です。
### データ解釈の精度向上
– 標準偏差によって得られる情報は、単なる平均値だけでは見えない傾向やパターンを明らかにします。
– データポイント間の関係性や異常値(アウトライヤー)の影響を評価する際にも役立ちます。
### 比較分析
– 異なるデータセット同士の比較が容易になります。例えば、「A社」と「B社」の売上高の標準偏差を見ることで、それぞれの企業活動や市場状況について深く理解できます。
– また、この比較によって戦略的な意思決定もサポートされます。
### リスク管理
– 標準偏差はリスク評価にも利用されます。投資など不確実性が伴う状況下では、リスクとリターンとの関係性を考慮するためにも必要です。
– 高い標準偏差は、高リスク・高リターンと解釈されることがあります。一方で低いものは安定した投資先として捉えられるでしょう。
| 特徴 | 説明 |
|---|---|
| 低標準偏差 | データポイントが平均近くに集まる。 |
| 高標準偏差 | データポイントが広範囲に分布し、多様性がある。 |
このように、「標準偏差 いくつ」が持つ意味合いやその背後には多くの洞察があります。次回以降も、この統計指標についてさらに詳しく掘り下げて行きたいと思います。
実際の例を通じて学ぶ標準偏差の計算方法
データ分析において、標準偏差を具体的な例を通じて学ぶことは非常に有益です。ここでは、実際の数値を使って「標準偏差 いくつ」を計算する方法を示します。このプロセスを理解することで、データの散らばりや変動性についてより深い洞察が得られます。
例題:テストの点数
例えば、あるクラスで5人の学生が受けた数学のテスト結果が以下のようだとします。
- 学生A: 80点
- 学生B: 85点
- 学生C: 90点
- 学生D: 70点
- 学生E: 75点
まず、このデータセットの平均(μ)を計算します。平均は次のように求めます。
[
text{平均} = frac{(80 + 85 + 90 + 70 + 75)}{5} = frac{400}{5} = 80
]
次に、それぞれのデータポイントから平均を引き、その結果を二乗します。
| 学生 | 点数 | 平均との差 | 平均との差² |
|---|---|---|---|
| A | 80 | (80 – 80) = 0 | (0^2 = 0) |
| B | 85 | (85 – 80) = 5 | (5^2 = 25) |
| C | 90 | (90 – 80) =10 | (10^2 =100) |
| D | 70 | (70 -80)=−10 | (−10^2=100) |
| E | 75 | (75 −80)=−5 | (−5^2=25) |
この表からわかるように、各学生による平均との乖離があります。そして、それらすべての平方和(Σ)を求めます。
[
Σ(text{平均との差²}) =0+25+100+100+25=250
]
最後に、この合計値をデータポイント数(n)で割ります。その後、平方根を取ります。
- 分散(σ²)の計算:
[
text{分散}=frac{250}{n}= frac{250}{5}=50
]
- 標準偏差(σ)の計算:
[
σ=sqrt{text{分散}}=sqrt{50}approx7.07
]
この結果から、「標準偏差はいくつ」と尋ねられた場合には約7.07という答えになります。この数字は、テスト結果がどれほどばらついているか、一目で理解できる指標となります。
結論
このような実際的な計算方法によって、「標準偏差」がどれだけ重要な情報源であるかが明確になるでしょう。また、この知識は他の統計分析にも応用できるため、多角的な視野でデータを見る手助けとなります。今後さらに複雑なデータセットや異なる状況でも適用可能なスキルとして身につけていただきたいと思います。
他の統計指標との比較と関係性
データ分析を行う際には、標準偏差だけでなく、他の統計指標との関係性も理解することが重要です。ここでは、平均、分散、および四分位範囲といった指標と標準偏差との比較を通じて、それぞれの役割や意味を明確にしていきます。
平均との関係
平均はデータセット全体の中心的な値を示しますが、標準偏差はその値からどれほどデータが散らばっているかを表します。たとえば、同じ平均値でも、その周りにどれだけの変動があるかによってデータの特性は大きく異なります。例えば、一つのクラスで全員が90点以上取っている場合と、一部は50点以下の場合では、平均は同じでも印象はまったく違います。このように、私たちは両方の指標を用いてデータを多面的に評価する必要があります。
分散との関連
分散(σ²)は実質的には標準偏差(σ)の二乗ですが、その数値自体から直接的な解釈は難しいことがあります。そのため、私たちは通常、直感的に理解しやすい標準偏差を使用します。分散が高ければ高いほど、それだけデータポイント間のばらつきが大きくなることを示しています。この関係性からもわかるように、高い分散値は必然的に高い標準偏差へと繋がります。
四分位範囲(IQR)との対比
四分位範囲とは、データセット内で上位25%および下位25%の境界値によって定義される範囲です。これは外れ値や極端な変動による影響を受けないため、多くの場合よりロバストな指標として扱われます。一方で、標準偏差は外れ値にも敏感であり、その影響によって数値が大きく変わる可能性があります。したがって、この2つの指標も組み合わせて使用することで、お互いの弱点を補完し合うことができます。
このように、「標準偏差 いくつ」と考える際には、それ単独ではなく他の統計指標と併せて見ることでより深い洞察を得られるでしょう。それぞれ異なる視点から我々の分析結果への理解や解釈力を強化し、有益な意思決定につながります。